Breaking News: Meta's Autonomous Agent Revolutionizes AI Hardware Efficiency
Meta has introduced KernelEvolve, an autonomous AI agent that writes and optimizes low-level kernel code for its diverse fleet of chips—NVIDIA GPUs, AMD GPUs, custom MTIA silicon, and CPUs. The system, now part of Meta's Ranking Engineer Agent, slashes weeks of human expert work into hours, delivering over 60% inference throughput improvement for the Andromeda Ads model on NVIDIA GPUs and more than 25% training throughput gain on Meta's custom MTIA chips.
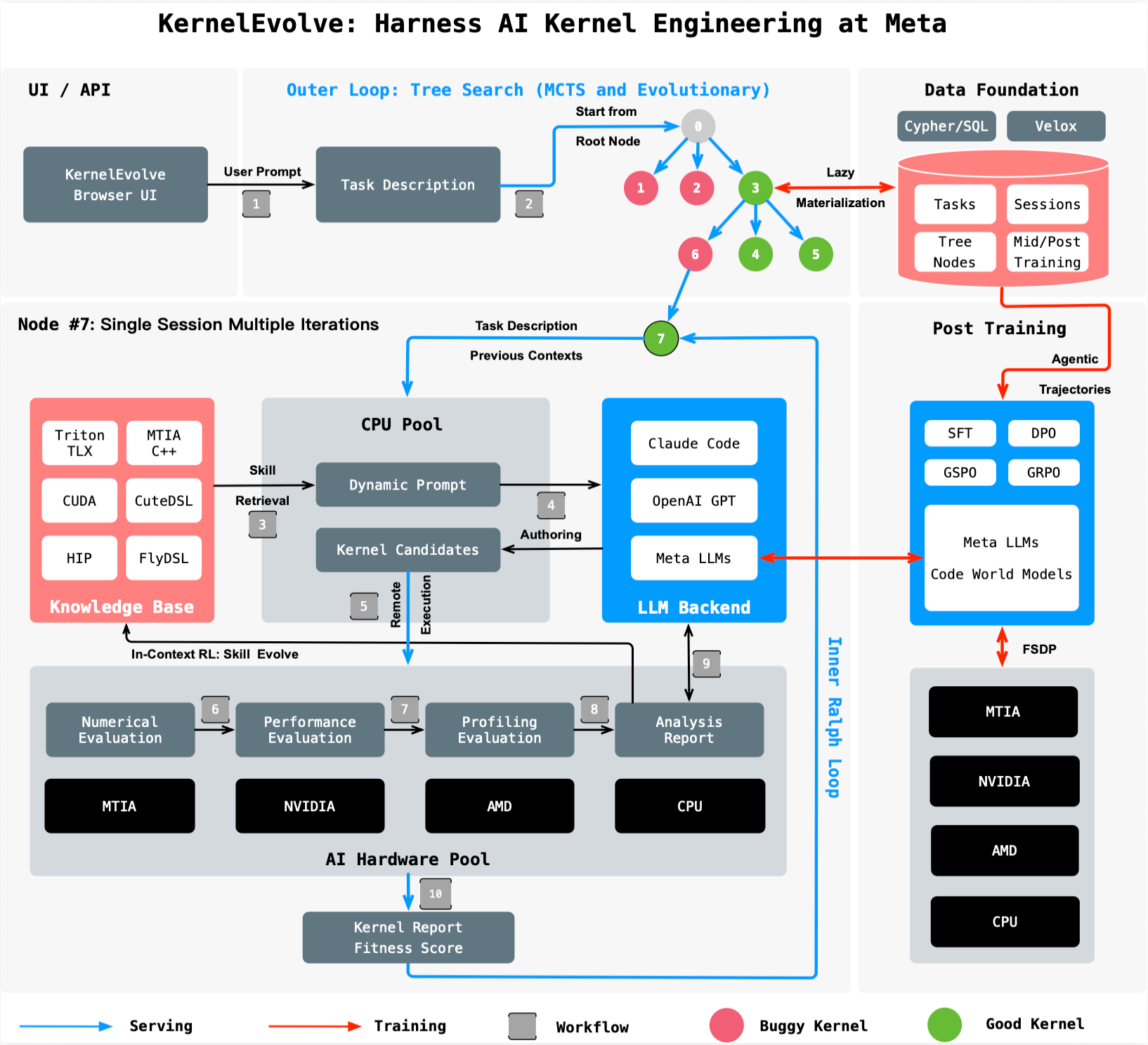
“KernelEvolve treats kernel optimization as a search problem,” a Meta spokesperson told reporters. “A job-harness evaluates each candidate kernel, feeds diagnostics back to the LLM, and drives a continuous search over hundreds of alternatives—often exceeding human-expert performance.” The breakthrough addresses the exponential complexity of supporting multiple hardware generations and model architectures, which had outpaced manual tuning.
Background: The Kernel Bottleneck
Meta operates a massive, heterogeneous infrastructure. Each new chip generation and ML model requires hand-crafted code—called kernels—that translates high-level operations into chip-specific instructions. Standard operators like matrix multiplications are covered by vendor libraries, but production workloads need many custom operators.
“The number of models multiplied by the number of hardware types and generations created a scalability crisis,” explained the spokesperson. “Hand-tuning by kernel experts simply doesn't scale.” KernelEvolve automates this process, compressing weeks of profiling, optimizing, and cross-hardware debugging into hours of automated search and evaluation.
What This Means: Faster Innovation, Lower Costs
By automating kernel authoring, Meta frees engineers to focus on higher-level model design rather than manual optimization. The system works across public and proprietary hardware, generating code in high-level DSLs like Triton, Cute DSL, and FlyDSL, as well as low-level languages including CUDA, HIP, and MTIA C++.
The performance gains translate directly into more efficient AI services—from personalized recommendations to generative AI assistants—served to billions of users every day. Full details appear in the paper, “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta,” set for the 53rd International Symposium on Computer Architecture (ISCA) 2026.
How It Works: An Agentic Search
KernelEvolve uses a large language model (LLM) as its core engine. It proposes candidate kernel implementations, which are then compiled and run on actual hardware. Diagnostic profiles are fed back to the LLM, which iterates to improve performance.
This agentic approach has already demonstrated results that rival or surpass human experts. For example, over 60% inference throughput improvement for the Andromeda Ads model on NVIDIA GPUs and over 25% training throughput improvement for an ads model on Meta's custom MTIA chips.
For more on Meta's autonomous AI capabilities, see the Ranking Engineer Agent blog series.